Es gibt Papiere, die man liest und bei denen man danach nickt. Nicht unbedingt, weil alles stimmt – sondern weil alles erstmal sehr plausibel klingt.
„Trustworthy Industrial AI“ ist so ein Paper. Die Autoren vom Fraunhofer Institut für Produktionstechnologie in Aachen versuchen darin, einen Rahmen zu entwickeln, der KI-Systeme in industriellen Umgebungen verlässlich und sicher macht. Ihr Ansatz: vier Kerndimensionen, an denen sich Entwicklung und Betrieb orientieren sollen: Transparenz, Robustheit, Sicherheit, Adaptivität. Dazu ein risikobasierter Ansatz und saubere Dokumentation.
Das liest sich logisch. Fast schon zwingend. Wer würde ernsthaft argumentieren, dass industrielle KI nicht transparent oder sicher sein sollte?
Und genau da liegt für mich der Haken: ist das ein echter Lösungsansatz oder viel mehr eine Wunschliste?
In der klassischen Automatisierung musste man sich darüber nie groß Gedanken machen. Systeme waren so gebaut, dass sie sich vorhersagbar verhalten. Wenn A, dann B. Wenn etwas schiefging, konnte man den Fehler suchen. Und meistens auch finden. Dieses Vertrauen kam nicht aus irgendeinem Framework – sondern aus der Natur der Systeme selbst.
Mit KI verschiebt sich das Ganze. Plötzlich heißt es: In den meisten Fällen vermutlich B. Das mag in vielen Situationen völlig ausreichen. In der Industrie, wo Prozesse stabil laufen sollen und Fehler schnell teuer werden, fühlt sich das aber erstmal wie ein Rückschritt an.
Die Kritik am Paper selbst
Frameworks sind wichtig. Sie schaffen Orientierung, machen Anforderungen sichtbar und helfen, Risiken systematisch zu denken. Das ist nicht nichts – gerade in einem Bereich, der so schnell wächst und so wenig reguliert ist wie industrielle KI.
Aber ein gutes Framework muss zwei Dinge leisten: Es muss intern konsistent sein. Und es muss in der Realität ankommen. Dieses Paper scheitert an beidem.
Das Operationalisierungsproblem
Die vier Dimensionen sind so abstrakt formuliert, dass sie für jeden Use Case gleich aussehen. Transparenz klingt gut – aber wie viel Transparenz ist ausreichend? Was gilt als transparent genug für eine Qualitätskontrolle, und was für eine Prozessoptimierung in einer Chemieanlage? Das Paper gibt darauf keine Antwort. Es definiert Kategorien, aber keine Kriterien. Keine Schwellenwerte. Keine Messmethoden. Wer das Framework anwenden will, steht am Ende mit denselben Fragen da wie vorher – nur mit vier neuen Überschriften.
Das ist kein marginales Versäumnis. Nehmen wir Robustheit; eine der vier Kerndimensionen. Das Paper definiert sie als die Fähigkeit, innerhalb des vorgesehenen Betriebsbereichs reproduzierbare Ergebnisse zu liefern. Klingt vernünftig. Aber was heißt das konkret für eine Schweißnahtprüfung, bei der Lichtverhältnisse, Materialcharge und Nahtgeometrie täglich variieren? Ab welcher Fehlerquote gilt ein Modell als nicht mehr robust genug? Wer legt das fest, und nach welchem Verfahren? Das Paper schweigt.
Das Datenproblem
Der zweite Bruch liegt tiefer. Das Paper benennt selbst, dass Produktionsdaten strukturell problematisch sind – inhomogen, unbalanciert, schlecht gelabelt. Und behandelt das dann als überwindbares Hindernis durch mehr Aufwand.
Das greift zu kurz. Denn in vielen industriellen Kontexten entsteht strukturell keine ausreichende Datenbasis – nicht wegen mangelnder Sorgfalt, sondern wegen der Natur des Problems selbst. Wer gute Qualitätskontrolle betreibt, hat wenig fehlerhafte Bauteile. Wer wenig fehlerhafte Bauteile hat, hat zu wenig Trainingsdaten für genau die Fälle, auf die es ankommt. Studien zeigen, dass bis zu 80% der Zeit in KI-Projekten auf Datenvorbereitung entfällt – und dass die Seltenheit bestimmter Fehlerbilder die Modellgenauigkeit in der Fertigung strukturell einschränkt. Defektdaten setzen voraus, dass ein Unternehmen Defekte hat. Das widerspricht direkt dem Bedarf an großen Datensätzen für leistungsfähige Modelle.
Kein Framework löst ein Datenproblem, das physikalisch begrenzt ist. Das Paper erwähnt diese Spannung – zieht daraus aber keine Konsequenz. Und das ist das Muster, das sich durch beide Abschnitte zieht: Kategorien ohne Kriterien, Anforderungen ohne Messmethoden, Probleme ohne Lösungsansatz. Was bleibt, ist das, was das Framework eigentlich überwinden wollte – eine gut gemeinte Absichtserklärung.
Ein Framework für wen?
Der dritte Bruch ist der folgenreichste. Die Autoren formulieren das Ziel ausdrücklich, kleine, mittlere und große Industrieunternehmen gleichermaßen anzusprechen. Aber wer die vier Dimensionen konsequent umsetzen will, braucht Data-Science-Expertise, belastbare IT-Infrastruktur, kontinuierliches Monitoring und die Kapazität, Modelle bei Veränderungen neu zu trainieren. Das ist kein einmaliges Projekt. Das ist dauerhafter Betrieb.
Die Autoren zitieren selbst Studien, die zeigen, dass viele Unternehmen wegen fehlendem Know-how und Kostendruck bei KI zögern. Und schlagen dann ein Framework vor, das genau dieses Know-how und genau diesen Aufwand voraussetzt. Empirisch liegt die KI-Implementierungsversagensrate bei KMU bei rund 80% – wobei 70% Ressourcenengpässe und 60% einen erheblichen Skills-Gap als Hauptgründe nennen. Gartner schätzt, dass bis zu 50% aller KI-Projekte bereits in der Pilotphase wegen schlechter Datenqualität abgebrochen werden.
Wer die Hürden für KI-Adoption senken will, kann kein Framework vorschlagen, das die Einstiegshürde de facto erhöht. Das Paper löst nicht das Problem, das es zu lösen vorgibt.
Das breitere Problem: KI in der Industrie
Soweit zur internen Kritik. Aber selbst wenn man dem Framework mehr Substanz zugesteht – es trifft auf eine Realität, die es nicht einkalkuliert.
Wo KI wirklich funktioniert – und warum
Das wird deutlich, wenn man sich anschaut, wo KI heute tatsächlich funktioniert. Visuelle Qualitätskontrolle: Kameras prüfen Bauteile auf Fehler. Das funktioniert erstaunlich gut, weil der Anwendungsfall eng ist, die Daten relativ klar sind und man das Ergebnis direkt messen kann. Entweder der Kratzer wird erkannt oder nicht. Predictive Maintenance: funktioniert, aber nur da, wo Ausfälle richtig weh tun und genügend Daten vorhanden sind. Bei einfachen Maschinen ist der Austausch oft billiger als die ganze KI-Infrastruktur drumherum. Prozessoptimierung in komplexen Anlagen, wo so viele Variablen zusammenspielen, dass klassische Regeln nicht mehr greifen – da kann KI tatsächlich Muster finden, die man sonst nicht sieht.
Was alle diese Beispiele gemeinsam haben: Sie sind klar eingegrenzt. Das Paper argumentiert aber eine Ebene darüber – und genau dort beginnen die Probleme, die kein Framework wegdefinieren kann.
Was passiert, wenn die Frage falsch ist
Das Paper benennt unter der Safety-Dimension das Problem fehlerhafter Eingaben. Aber es zieht die Konsequenz nicht zu Ende. Denn das eigentliche Risiko ist nicht der adversariale Angriff von außen, sondern die schleichend falsche Annahme von innen: eine schiefe Datenbasis, ein falsch gestelltes Problem, eine Prämisse, die niemand hinterfragt hat. Der BullshitBench hat das systematisch getestet – mit 100 Fragen in fünf Fachgebieten, die bewusst frei erfundene Fachbegriffe und Phantasiekonzepte enthielten. Das Ergebnis: Die meisten Modelle spielen mit. Statt eine Prämisse zurückzuweisen, bauen sie darauf auf und liefern Antworten, die kohärent klingen. Ein System, das auf falschen Annahmen weiterfährt ohne Alarm zu schlagen, ist kein sicheres System – egal wie sauber das Framework drumherum ist.
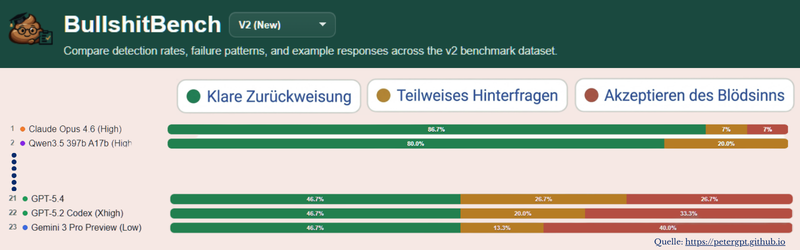
80 Prozent übernehmen das falsche Ergebnis
Jetzt könnte man sagen: Dafür ist ja der Mensch da. „Human in the loop.“ Jemand, der draufschaut und eingreift. Aber auch das ist weniger beruhigend als es klingt.
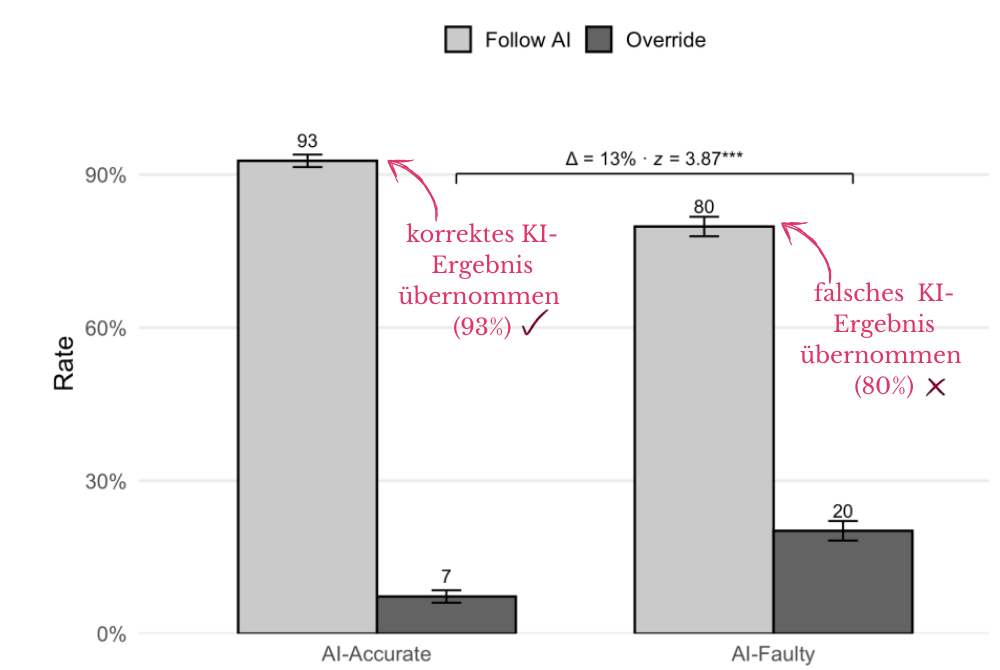
Eine Studie der Universität Pennsylvania untersuchte mit 1.372 Teilnehmern und knapp 10.000 Einzelentscheidungen, wie Menschen mit KI-Fehlern umgehen. Die KI wurde dabei so manipuliert, dass sie in der Hälfte der Fälle falsche Antworten lieferte. Wenn die KI richtig lag, übernahmen 93% das Ergebnis. Wenn sie falsch lag, übernahmen immer noch 80% das falsche Ergebnis. Finanzielle Anreize und direktes Feedback verbesserten die Überprüfungsbereitschaft – eliminierten den Effekt aber nicht.
In einer Produktionsumgebung läuft das dann so: Die Anlage läuft, das System gibt eine Empfehlung, der Mensch bestätigt sie – nicht weil er sie geprüft hat, sondern weil sie plausibel aussieht und gerade keine Zeit ist.
Was wir verlernen, während das System dazulernt
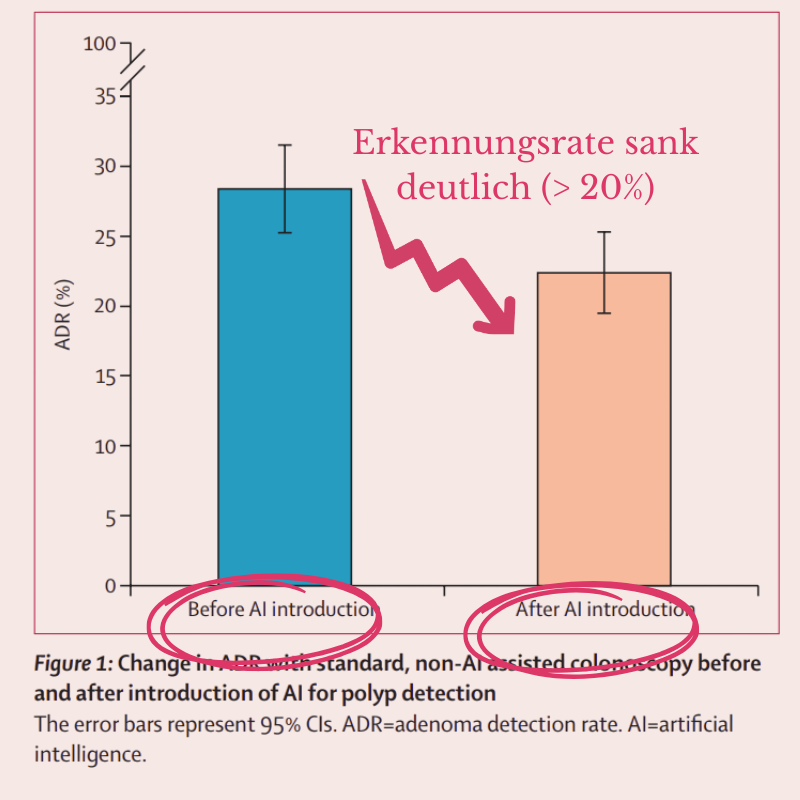
Und dann kommt noch etwas dazu, das man gerne ausblendet. Eine polnische Studie, veröffentlicht im Lancet, beobachtete 19 erfahrene Ärzte über insgesamt 1.443 Darmspiegelungen. Nach einer Phase mit KI-Assistenz entdeckten dieselben Ärzte ohne KI-Unterstützung signifikant weniger krebsindizierende Polypen als zuvor. Eine Anthropic-eigene Studie mit 52 Entwicklern zeigte Ähnliches: Wer beim Erlernen einer neuen Python-Bibliothek KI-Unterstützung hatte, schnitt im anschließenden Wissenstest deutlich schlechter ab als die Gruppe ohne. Das System wird besser – und man selbst verlernt ein Stück von dem, was man auslagert. Die Abhängigkeit wächst still, während die Kompetenz schwindet. Für ein Framework, das Vertrauen in KI stärken will, ist das eine unbequeme Nebenwirkung.
Die Rechnung, die niemand aufmacht
Jede der vier Dimensionen ist ein dauerhafter Aufwandsblock. Transparenz kostet Zeit und Komplexität. Robustheit kostet Daten, Tests und Infrastruktur. Sicherheit kostet Redundanz. Adaptivität bedeutet laufenden Betrieb, Retraining, Monitoring. KI ist kein Projekt, das man einmal implementiert und dann läuft’s.
Viele Probleme in der Industrie sind nicht deshalb ungelöst, weil es keine KI gibt – sondern weil sie mit klaren Regeln, sauberer Sensorik und durchdachter Prozessgestaltung lösbar wären. KI kommt eigentlich erst dann sinnvoll ins Spiel, wenn die Komplexität so hoch ist, dass klassische Ansätze nicht mehr reichen. Und genau dann wird Kontrolle schwieriger, nicht einfacher.
Das Paper argumentiert: Wenn wir diese vier Dimensionen berücksichtigen, wird KI vertrauenswürdig und damit breit einsetzbar. Ich würde sagen: Wenn wir diese vier Dimensionen wirklich berücksichtigen, wird KI erst einsetzbar – aber oft so teuer, dass sich die Frage stellt, ob klassische Automatisierung nicht die bessere Wahl gewesen wäre. Je breiter man KI einsetzen will, desto größer werden die Unsicherheiten und desto mehr Aufwand muss man betreiben, um sie zu kontrollieren. Irgendwann kippt das Kosten-Nutzen-Verhältnis.
Das Framework macht KI verwaltbar. Vertrauen im klassischen industriellen Sinne – eng verknüpft mit Kontrolle und Vorhersagbarkeit – ist damit noch nicht gewonnen.
Related Posts

Von Mainstream, Nischen und Neugier
Wann habt Ihr zuletzt eine Doku über Syphilis geschaut? Ich erst vergangene…

Die Freude des Abschaltens
Das Internet nimmt sehr rapide einen immer größeren Stellenwert im Leben der…

Kopfloses Sammeln vs. gekonntes Kuratieren
An die 22.000 Fotos hatten sich auf meinem Handy angesammelt. Wenn ich Freunden…